深度学习在表情识别中的应用
本文的表情识别指的是给出一张图片,检测其中人脸的表情(如果含有人脸的话)。所有可能的表情种类往往事先约定好,粗分可以分为
positive、negative、neutral
三种,细分可以分为 neutral, angry,
surprise, disgust, fear,
happy, sad
7种或者更多种,这里的类别可根据具体采用的数据集进行调整,从机器学习的角度来说,这实际上就是一个多分类问题。
本文主要讲述如何将深度学习应用在表情识别中,以及在图像分类中深度学习一些常用方法,如采用预训练的模型进行特征的提取,用数据集对预训练的模型进行 Fine-tunning,而这实际上又牵涉到了迁移学习。
之所以采用深度学习的方法,是因为深度学习中的网络(尤其是CNN)对图像具有较好的提取特征的能力,从而避免了人工提取特征的繁琐,人脸的人工特征包括常用的 68 个 Facial landmarks 等其他的特征,而深度学习除了预测外,往往还扮演着特征工程的角色,从而省去了人工提取特征的步骤。下面首先讲述深度学习中常用的网络类型,然后讲述通过预训练的网络(经过ImageNet进行预训练)对图像提取特征,以及对预训练的网络采用自己的数据进行微调的 Fine-Tunning。
数据集
表情识别中常用的数据集有 CK+, MMI, JAFFE, KDEF等,这些数据有些是短视频,有些是图片序列(记录一个表情的若干张图片),有些则是单张表情图片。
在训练时,需要根据实际的应用场景以及采用的模型的输入格式将这些数据集处理成相关格式,这里不在详细说明。
网络类型
假如采用深度学习中常用的网络层 cnn,rnn, fully-connect 等层组合成网络,那么具有非常多种的选择,这些网络的性能需要在实际任务中检验,而经过实践发现,某些网络结构往往在图像分类上具有较好的结果,如ImgeNet比赛中提出的一些列模型:AlexNet,GoogleNet(Inception), VGG, ResNet 等。这些网络已经经过了 ImageNet 这个数据集的考验,因此在图像分类问题中也常被采用。
至于网络的结构,往往是先通过若干层 CNN 进行图像特征的提取,然后通过全连接层进行非线性分类,这时的全连接层就类似与MLP,只是还加入了 dropout 等机制防止过拟合等,最后一层有几个分类就连接几个神经元,并且通过 softmax 变换得到样本属于各个分类的概率分布。如下是 AlexNet 的网络结构图
AlexNet
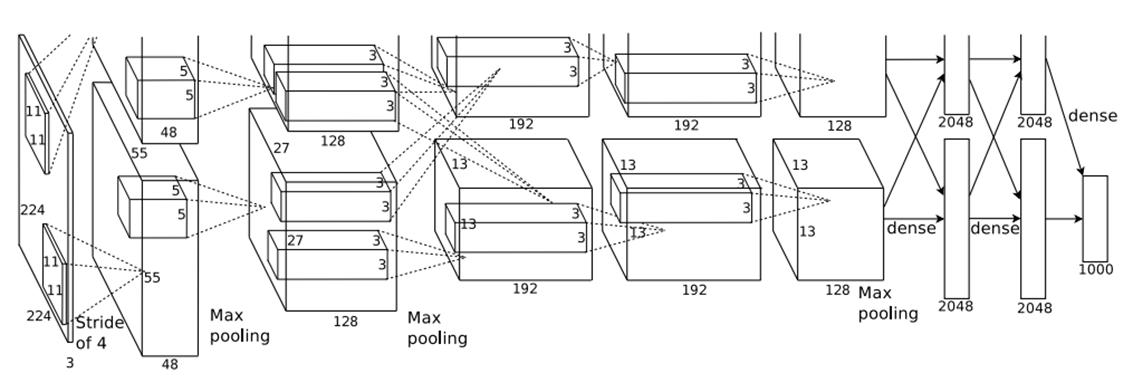
关于AlexNet 更详细的介绍可参考这篇文章。
Inception
而 Inception 是 Google 研发的一个深度神经网络,经历了四个版本 (也叫GoogLeNet),各个版本及其对应的论文如下,各个版本
[v1] Going Deeper with Convolutions, 6.67% test error, http://arxiv.org/abs/1409.4842 [v2] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, 4.8% test error, http://arxiv.org/abs/1502.03167 [v3] Rethinking the Inception Architecture for Computer Vision, 3.5% test error, http://arxiv.org/abs/1512.00567 [v4] Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning, 3.08% test error, http://arxiv.org/abs/1602.07261
Inception 的结构与前面的 AlexNet 的大同小异,其核心是多了 Inception 模块,而 Inception 模块的结构如下
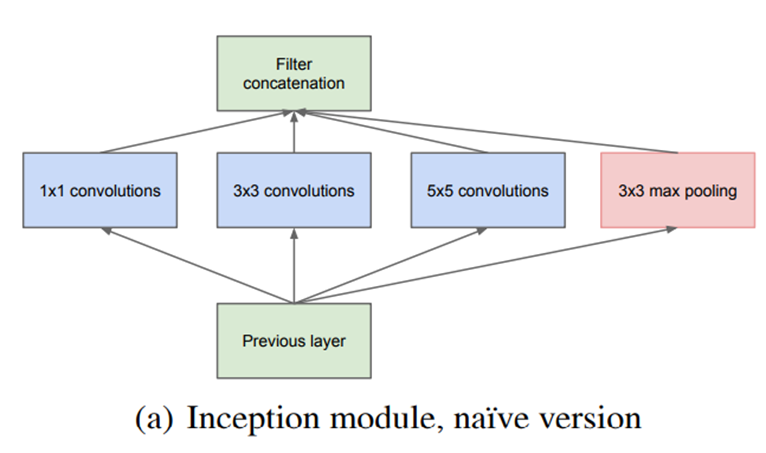
Inception 模块使得网络的当前层可以通过多种方式从前一层网络提取特征,如上图通过了三种不同大小的卷积层以及一个池化层,然后将这些特征进行 concate 送到下一层。
如下是 Inception V3 的结构
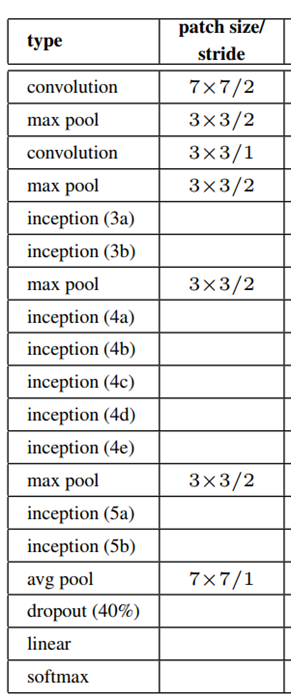
VGG
VGG 并没有采用很新颖的结构,整个网络只是采用了 3X3 的卷积层以及 2X2 的池化层,但是层数比较深,就是这么一个靠两种简单网络层堆叠起来的网络,却在 ImageNet 比赛上取得了非常好的结果。VGG 主要工作是证明了增加网络的深度能够在一定程度上影响网络最终的性能,越深的网络能够容纳更多数据的信息,对于更大的数据具有更好的效果,VGG整个网络的结构如下
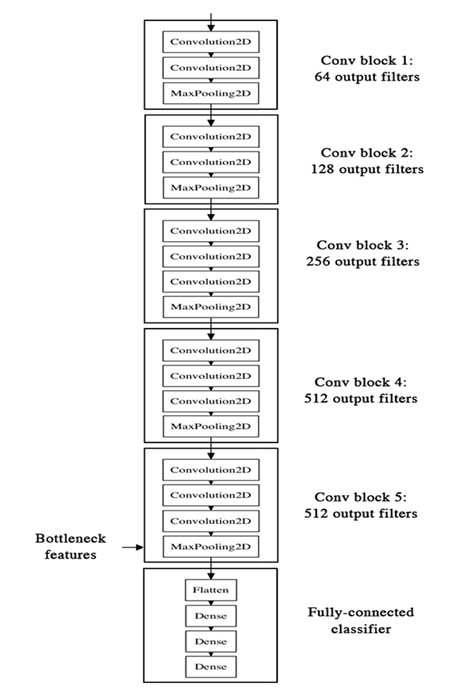
ResNet
前面 VGG 提到了网络的深度(层数)起到了一个非常重要的作用,但是如果只是简单地将层堆叠在一起,增加网络的深度并不会起太大作用。这是由于梯度消失和爆炸(vanishing/exploding gradient)问题,深层的网络很难训练。因为梯度反向传播到前一层,重复相乘可能使梯度无穷小。结果就是,随着网络的层数更深,其性能趋于饱和,甚至开始迅速下降。
而为了解决因深度增加而产生的性能下降问题, ResNet 引入一个“身份捷径连接”(identity shortcut connection),直接跳过一层或多层,如下图所示:
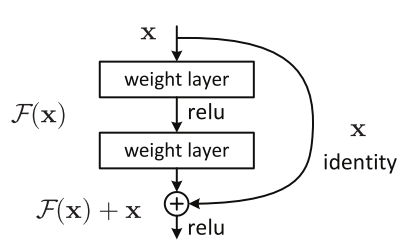
提出 ReNet 的这篇论文指出,假设目标映射为 \(H(x)\),这个模块并不是让 stacked layers 去直接拟合这个目标映射,而是去拟合残差 \(F(x) := H(x)-x\),则拟合的 \(H(x)\) 则变为了 \(F(x) + x\), 论文假设优化残差 \(F(x)\) 比优化 H(x) 更容易。
上面这段话基本翻译自提出 ResNet 这篇论文,更直观的理解就是每一层不仅仅只是能从前一层获取信息了,而是还可以从更前面的几层获取,而 ResNet 最开始的只是建单地将更前面几层的 x 直接加到当前层的输出,也就是 \(F(x) + x\), 而 ResNet 的若干变体则对这部分直接传递的 \(x\) 进行了处理,如通过卷积层等操作,但是其核心思想还是跨层连接从而获得更多的信息。
最开始提出的 ResNet 的结构如下

CNN-LSTM
上面的模型均是对单张图像进行处理,但是还有一种模型是对连续图片 sequence 进行处理的,由于连续图片 sequence 包含了时序信息,因此通过将 CNN 与 RNN 进行结合对时序图片列进行预测。在表情识别中
CNN-LSTM 是将 CNN 与 LSTM 结合起来的一种模型,其基本结构如下,图片出自该论文
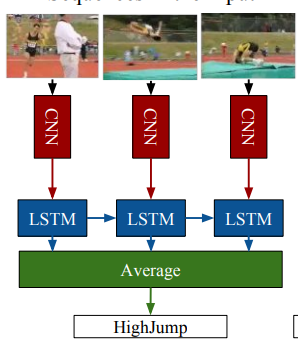
其思想就是首先通过 cnn 提取每张图片的特征,然后将这些带时序的特征传入 LSTM 中,可以取每一个 LSTM 的输出进行平均后连接 softmax 进行输出,也可以直接取最后一个 LSTM 的输出连接 softmax 作为输出。
上面这些网络训练的时候均是通过 SGD 进行反向传播,某些会加入 momentum 等其他改进。
这些网络理解起来可能问题不大,但是如果要代码实现起来的话工作量并不小,好在已经有了若干框架实现了这些模型,在使用时直接调用即可,这里以最简单的框架 Keras 为例说明,Kreas 已经在这里列出了一些实现的网络,可以参考其文档直接进行调用。
预训练模型提取特征
上面提到的这些模型少则十几层,多则上百层,其参数数目也达到了百万级别,要训练这么庞大的一个网络,如果数据量不足,很容易会会导致整个网络过拟合(当然,如果训练epoch次数少,也会直接导致欠拟合)。
而在实际中,像 ImageNet 这种庞大的数据集很少,而且某些只是归少数大公司所有,假如个人或缺乏数据的小公司需要用到上面提到的网络时,那就是无米之炊了,因此在实际中使用时,往往不是从头开始训练一个很大的模型,而是采用下面提到的通过模型提取特征以及对模型进行 Fine-Tunning 的方法。
深度学习中的网络的一个好处就是,经过大规模数据集训练过后的,网络具有了抽取图像特征的特性,而抽取出来的图像的特征,跟实际要处理任务没有关系,也就是说经过 ImageNet 训练过后的网络,也可以用于表情识别中抽取人脸的特征,然后用这些特征再训练一个小一点的模型,如 Logistics Regression, SVM等,这时候的网络完全就是在扮演着一个自动特征工程的角色。
这里“通过网络提取的特征”往往指的是网络最后的某个全连接层的输出值,具体采用哪一层取决于后续处理所需的特征维数。
Keras 也提供了经过 ImageNet 预训练的一些模型,通过这些模型抽取图像特征的样例代码如下
1 | from keras.applications.vgg19 import VGG19 |
在实际测试时,用 VGG16 抽取图像的特征后再经过带 L1 正则化的Logistics Regression,再CK+上进行10-fold cross validation, 得到的准确率约为85%, 也说明了这种方法的有效性。
对预训练模型进行微调(Fine-Tunning)
上面通过预训练的网络提取特征的确有效果,但是这些经过预训练的网络基本都是在 ImageNet 数据集上进行训练的,而实际中的各种任务是千差万别的,光凭 ImageNet 是难以涵盖各个领域的需求的。
因此很自然会想到在预训练的网络基础上,用涉及到的具体任务中的数据集再次训练这个网络,从而让这个网络能够学习到这个数据集内的信息,这种方法也称为 Fine-Tunning。
Keras 的官方blog也写了一篇文章专门阐述这种方法,文章链接为 https://blog.keras.io/building-powerful-image-classification-models-using-very-little-data.html
在这篇文章中,并没有调整整个网络的参数,而是只调整了最后的几层卷积层和全连接层,文章称原因是越底层的卷积层所提取到的图像的特性越是有共性的特征,而越上层的卷积层提取的特征则越是跟具体的领域相关的,当然,到底要调整多少层,还取决于所拥有的数据量,另外,往往还会去掉网络最后的若干层,并根据实际的图像分类数目构建最后一层大小。
通过 Keras 进行 Fine-Tunning 的样例代码如下
1 | from keras.applications.vgg19 import VGG19 |
最后讲的利用了预训练模型的两部分实际上可以归入到迁移学习的范畴了,原因是我们利用了模型在 ImageNet 上学到的知识,迁移到了一个新的领域(表情识别),同理,也可以将其推广至医学影像等领域,当然,迁移学习远不止这点内容,有兴趣的可以去查找相关资料,这里不在论述。