计算广告笔记(3)--受众定向
这一讲主要介绍了受众定向的概念和若干种定向的方法。
受众定向概念
受众定向是目前广告系统的核心部分,要做的就是根据人群划分进行广告售卖和优化。
受众定向可以认为是为 AUC(Ad,User,Context)打标签的过程,上下文标签可以认为是即时受众标签,如下所示是AUC上的标签类别
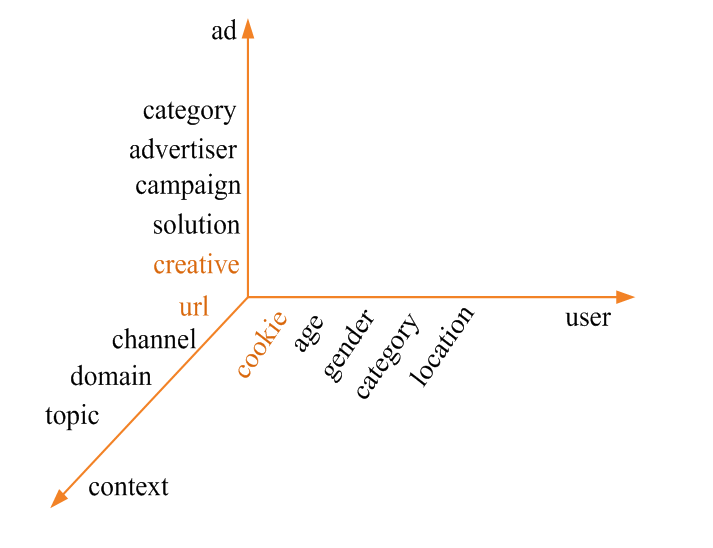
标签的两大主要作用 1. 建立面向广告主的流量售卖体系,注意这些特征需要有具体的意义才能展现给广告主,一般通过事先定义而不是通过文本聚类方法获取 2. 为各估计模块(如CTR预测)提供原始特征
下图的定向方式从右到左效果逐渐变好,从上到下表示不同阶段的定向方式;
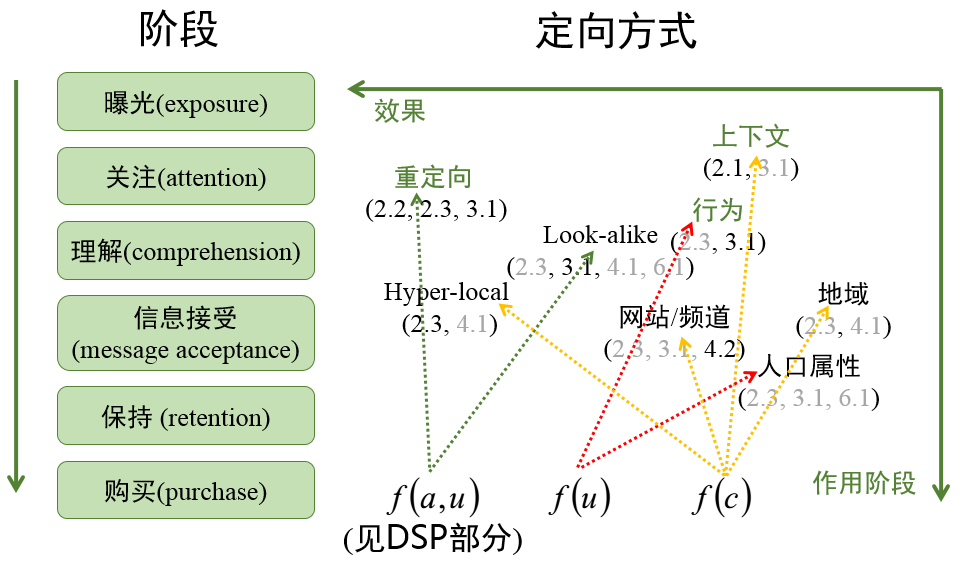
上图中的 \(f(u)\), \(f(c)\), \(f(a,u)\) 含义如下:
\(f(u)\):用户标签,即根据用户历史行为给用户打上的标签 \(f(c)\):上下文标签,即根据用户当前的访问行为得到的即时标签 \(f(a,u)\):定制化标签,也是一种用户标签,但是是针对某一广告主而言
除了上面提到的三种标签还有一中标签 \(f(a)\) 表示广告标签,便于与上下文标签或用户标签做匹配。广告标签常常有两种选择 1)直接将广告投放中的广告主、广告计划、广告组、关键词等直接作为标签 2)用人工的方式归类
除此之外,各种定向方式中的数字表示该方式有利于某个个阶段需要遵循的原则,各个阶段及其需要遵循原则如下所示
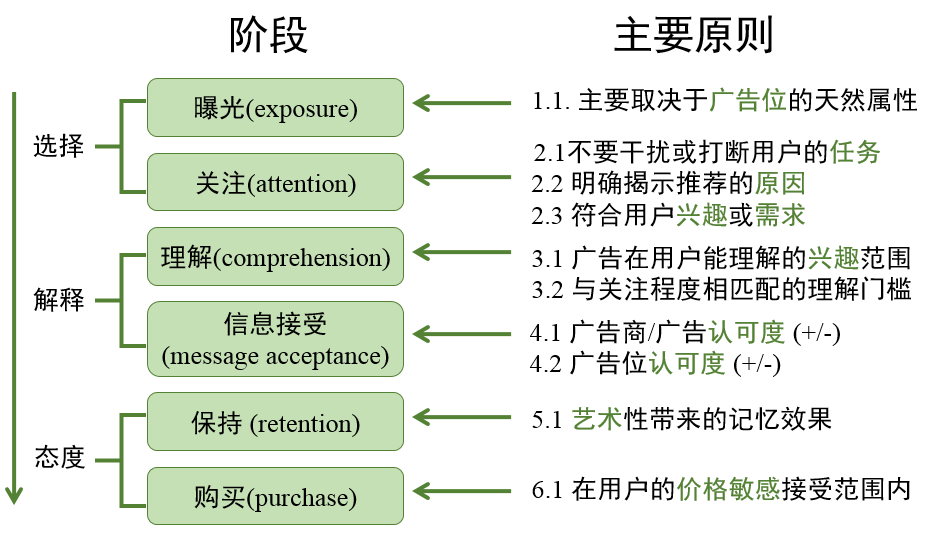
各种定向方式含义如下所示: 重定向:如果用户曾经访问过广告主的网站,就会给用户推该广告主的广告。(品牌广告较为常用) 上下文:用户目前浏览的网页内容相关的广告 行为:根据用户的历史行为进行推荐 网站/频道:根据网站的属性投放与该网站内容相关的某一领域的广告(如汽车广告) Hyper-local:将定位做得更细(如定位到某条街道的小饭馆,一般在移动广告较容易实现) Look-alike:一般来说重定向的量比较少,该方式可以找到与广告主提供的种子用户相似的用户进行广告投放 人口属性:人口,性别,教育水平,收入水平等,主要给广告商看,效果不是很好 地域:主要给广告商看,效果不是特别好
下面介绍一下audience targeting 在业界的一种商业模式
Audience Science 是一个做audience targeting的第三方发公司,其核心业务有两个:
- 主要提供面向publisher(如NewYork Times)的数据加工服务,从publisher提供的数据中提取出用户标签供 publisher 使用
- 直接运营ad network,并帮助广告主进行campaign管理和优化;该过程中会通过上面提取出来的用户标签优化效果,同时使用标签创造的营收按照一定比例跟publisher分成
行为定向
根据用户的历史行为给用户打上标签(上面提到的\(f(u)\)),下面是九种重要原始行为(按信息强度排序,往往强度越大,量越少)
- Transaction, 就是用户购买行为
- Pre-transaction, 用户购买前的一些行为,如商品浏览、加入购物车等
- Paid search click, 搜索广告中的点击行为
- Ad click, 广告的点击行为
- Search click, 搜索引擎上的点击行为
- Search, 搜索引擎上的搜索行为
- Share, 分享行为,如微博等
- Page View, 浏览页面的行为,注意这个页面不是上面搜索出来的页面,而是用户在某个站点中只能看到的页面(如贴吧),量大但是效果一般
- Ad view,看某个广告的次数,但是带来的效果往往是负面的
行为定向计算的一种方式如下 (\(t^{(i)}(u)\)表示用户 \(u\) 在标签 \(i\) 上的强度)
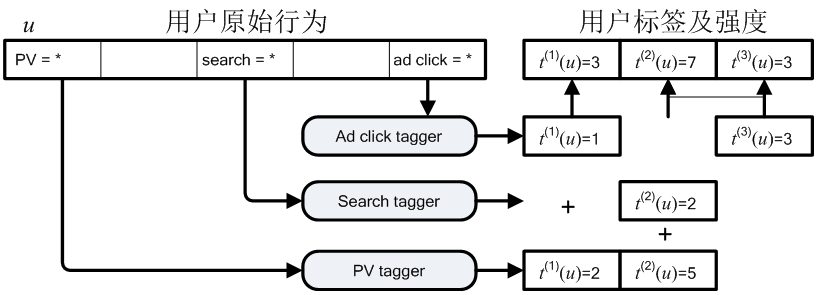
上面的方式比较简单,但是在海量数据中首先要做的是shallow的挖掘。
行为定向的还有其他一些问题:如 session log 和 long-term 行为定向
Session log
session log 关系到怎么从日志文件中提取出所需数据,有以下两点建议
- 将各种行为日志整理成以用户ID为key的形式,完成作弊和无效行为标注,作为各数据处理模块的输入源
- 可以将targeting变成局部计算,大大方便整个流程
Long-term 行为定向
Long-term 行为定向指的是如何从用户的长期行为中提取出用户的标签,常用的有两种方法:滑动窗口方式和时间衰减方式。
滑动窗口方式:直接将前面 \(T\) 天的行为标签进行相加。下面的公式中 \(f\) 为 long-term 标签,下标为日期
\[f_d^{(i)}(u) = \sum_{j=0}^T t_{d-j}^{(i)}(u)\]

时间衰减方式:按照时间衰减方式,对前n天的标签进行相加,时间越长,权重越小。这种方式空间复杂度低,仅需昨天的 \(f\) 和今天的 \(t\)
\[f_d^{(i)}(u) = t_{d}^{(i)}(u) + \alpha f_{d-1}^{(i)}(u)\]

实际中上面两种方法的效果差异不大,但是时间衰减方式的计算代价较小。\(T\) 的选择与实际商品相关,如汽车的 \(T\) 往往较大,而运动鞋的 \(T\) 往往不大,目前这个值主要是根据经验来设。
如何评判为用户打的标签?
受众定向评测可以借助Reach/CTR曲线,该曲线如下所示,横轴表示reach到的用户,纵轴表示广告点击率
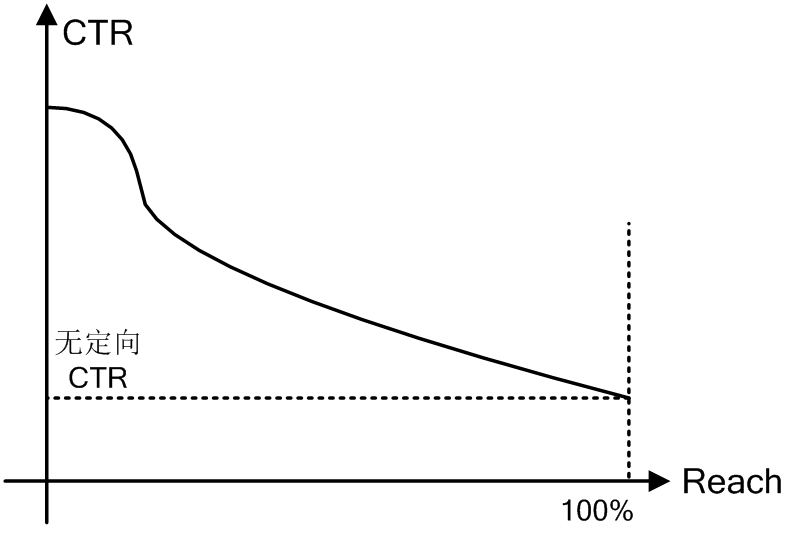
上图从左到右阈值设置逐渐变小,设为0时,可以reach到所有人,但是这个时候就相当于无定向投放了
注意拐点以及该曲线是否服从一个递减的趋势;如果不是递减,可能标签没意义,而拐点可以知道设置在哪一个值能够将有更强的购买倾向的人群与其他人群分开。
上下文定向
上下文定向指的是根据用户的访问内容给用户打标签 (上面提到的 \(f(c)\)),这样的定向中有一些根据广告请求中的参数经过简单运算就可以得到,如地域定向,频道/URL 定向、操作系统定向等。另外一类则是根据上下文页面的一些特征标签,如关键词、主题、分类等进行定向,下面重点讨论这种上下文定向方式。
上下文定向(打标签)主要有以下几种思路: 1)用规则将页面归类到一些频道或主题分类,如将 auto.sohu.com 归类到“汽车”的分类中 2)提取页面的关键词 3)提取页面的入链锚文本中的关键词,这需要一个全网的爬虫作支持 4)提取网页流量来源中的搜索关键词,这种方法除了页面内容,也需要页面访问的日志数据作支持 5)用主题模型将页面内容映射到语义空间的一组主题上
半在线抓取系统
确定了对上下文页面打标签的方法后,在在线广告投放时,页面标签系统需要某个查询 url 返回其对应的标签。在广告系统中,可以通过半在线(Near-line)上下文定向系统实现这个事情,如下就是一个 Near-line 上下文定向系统
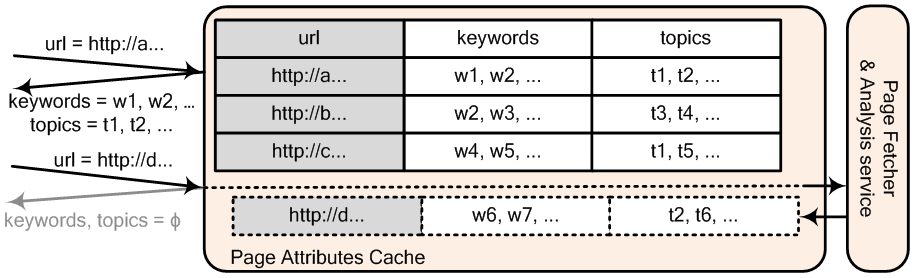
该系统用一个缓存(Redis)来保存每个 URL 对应的标签,当在线广告请求到达的时候,执行如下操作
- 如果请求的上下文 URL 在缓存中存在,直接返回其对应的标签
- 如果 URL 在缓存中不存在,为了广告请求能够及时得到处理,立刻返回空的标签集合,同时向后台的抓取队列中加入此 URL 进行抓取和存储
- 考虑到页面的内容会不定期更新,可以设置缓存合适的 TTL 以自动更新 URL 对应的标签
步骤 2 中能够返回空标签的原因是在广告系统中,某一次展示时标签的缺失带来的影响是可以忍受的,因为对于广告系统而言,这部分只是起到一个锦上添花的作用。
主题模型
除了直接提取页面内容的关键词作为页面的特征以外,还可以通过主题模型(Topic models)这一类模型对文本进行聚类得到文本的主题分布情况。
主题模型分两大类:有监督和无监督的。有监督指的是预先定义好主题的集合,用监督学习的方法将文档映射到这一集合的元素上;无监督指的是不预先定义主题集合,而是控制主题的总个数或聚类程度,用非监督的方法自动学习出主题集合以及文档到这些主题的映射函数。
广告中的主题挖掘有两种用途
- 用于广告效果优化的特征提取
- 用于售卖给广告主的标签体系
对于第一种用途, 用有监督或非监督的方法都可以;对于第二种用途,应该优先考虑采用监督学习的方法,因为这样可以预先定义好对广告主有意义而且可解释的标签体系。下面先介绍非监督方法,再介绍监督方法。
非监督方法
非监督的主题模型的发展经历了 LSA -> PLSA -> LDA 的过程,下面简单介绍这三种模型。
LSA(Latent Semantic Analysis) 有时也叫 LSI(Latent Semantic Indexing),这种方法实际上是将 SVD 分解应用到了 “文本-单词” 矩阵中,即
\[X \approx U \Sigma V^T\]
\(X\) 矩阵中的值有多种选择:0-1,出现次数,TF-IDF值。则 \(U\) 矩阵的一行对应的就是一篇文本在各个主题上的分布, \(V\) 矩阵每行对应的就是一个单词在各个主题上的分布,而选择奇异值的个数则决定了隐含主题的个数,也就是代表文本或词语的向量的维度。通过比较向量间的余弦相似性,便可比较文本或单词间的相似性。
这样的方法虽然直观,但是有几个问题,一是分解后矩阵 \(U\)、\(V\) 中可能存在着负值,二是这些数值在概率上没有意义。为了解决这些问题,便提出了PLSA。
PLSA(Probabilistic Latent Semantic Analysis)可以说是概率化了的LSA,但是采用的方法与 LSA 完全不同,PLSA 没有涉及到 SVD,而是采用混合模型的做法。
PLSA 方法假设文本包含多个主题,这些主题服从多项式分布,而每个主题下的有多个词,这些词也服从多项式分布。假设有 M 篇文档,每篇文档有 N 个词,则生成这 M 篇文档的过程通过有向图模型表示如下
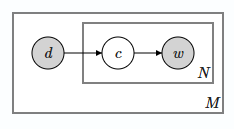
在有向图模型中,灰色的点表示能够观察到的点,其他白色的点表示需要求解的点,而最后需要求解的点是没有入度的点,其他的有入度和出度的点会被积分积掉,框及其框内符号表示框里面的内容重复若干次
而上图中 \(d\) 表示文本,\(c\) 表示主题, \(w\) 表示词语,且文本 \(d\) 中生成词语 \(w_i\) 的概率是
\[P(w_i|d) = \sum_c P(c|d) P(w_i|c)\]
其中 \(P(c|d)、 P(w|c)\)均服从多项式分布
则整篇文本生成的概率为
\[P(d) = \prod_i P(w_i|d) \]
这个模型跟混合高斯模型(mixture of Gaussian)非常相似,都是融合了多个指数族分布的模型,这一类模型也可以称为混合模型,而求解这一类的问题的方法便是 EM 算法,这里不详细展开。除此之外,假如将上面 PLSA 中文本主题服从的多项式分布改为伽马分布,将主题下的词语服从的多项式分布改为泊松分布,那么 PLSA 就变为了GaP(Gamma-Poisson)模型。
LDA(Latent Dirichlet Allocation) 则是在 PLSA 的基础上为其两个多项式分布加上了贝叶斯先验, 先验选为 Dirichelet 分布,原因是更多是数学上的便利性,因为Dirichelet 是 multinational 的共轭先验,容易求解。
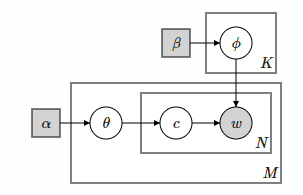
上图中 \(\alpha\), \(\beta\) 表示参数为 \(\alpha\), \(\beta\) 的狄利赫里分布,这两个分布分别是文本的主题概率分布和主题下词语的概率分布的先验分布。文本的主题概率分布的先验分布为
\[ \theta_i \sim Dir(\alpha),~i=1, 2...M \]
\(\theta_i\) 表示第 \(i\) 篇文档的主题分布,而 \(\theta_{i,k}(k=1,2...K)\) 表示第 \(i\) 篇文档中包含第 \(k\) 个主题的概率
而主题下的词语的概率分布的先验分布为
\[ \phi _k \sim Dir(\beta),~k=1,2...K \]
\(\phi_k\) 表示第 \(k\) 个主题下的词语分布,而 \(\phi_{k,j}(j=1,2...V)\) 表示第 \(k\) 个主题中包含第 \(j\) 个词的概率,\(V\) 为语料库的词表的大小
确认先验分布后,文档中的主题分布以及主题下的词语分布均服从多项式分布,与 PLSA 相同,求解 LDA 得思路是先求解出其最终的联合概率分布,然后通过 Gibbs Sampling 收敛到该概率。
经验贝叶斯(Empirical Bayes)
如下图模型, 如何确定hyperparameter \(\eta\)?
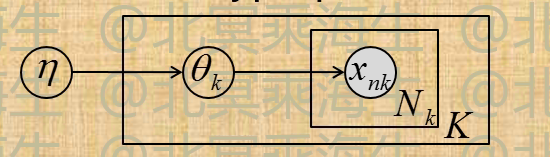
用 Empirical Bayes 估计的解为:\[\widehat \eta = arg \max_{\eta} \int \prod_{k=1}^{K}p(D_k|\theta_k)p(\theta_k|\eta)d\theta_k\]
当 \(p(x|\theta)\) 为指数族分布,\(p(\theta|\eta)\) 为其共轭先验时,可用EM求解, 其中E-step为Bayesian inference过程, 由 \(\eta^{old}\) 得到后验参数 \(\widetilde \eta_k^{old}\) , 而M-step为:\[(\theta, ln[g(\theta)])_{\eta^{new}} = \frac{1}{K}\sum_{k=1}^{K}(\theta, ln(g(\theta)))_{\widetilde \eta_k^{old}}\]
从经验贝叶斯看LDA
LDA可以视为PLSI的经验贝叶斯版本,由于PLSI不是指数族分布,而是其混合分布,因此其贝叶斯版本不能使用前面的EM算法。工程上常用的求解方法有两种:Deterministic inference 和 Probabilistic inference
Deterministic inference: 可用变分近似,假设z和θ的后验分布独立迭代求解过程与EM非常相似,称为VBEM,但是在大多数问题上无法保证收敛到局部最优
Probabilistic inference: 可用Gibbs-sampling(Markov-chain Monte-Carlo, MCMC 的一种),以概率1收敛到局部最优值;还有一种方法是 Collapsed Gibbs-sampling
Topic model的并行化
- EM及VBEM的并行化较为简单
- E-step(mapper): 可以方便地并行计算
- M-step(reducer): 累加E-step各部分统计量后更新模型
- 将更新后的模型分发到新的E-step各个计算服务器上
- AD-LDA: Gibbs Sampling的并行化
- Mapper: 在部分data上分别进行Gibbs sampling
- Reducer: 全局Update
\[n_{i,j} \leftarrow n_{i,j}+\sum_p(n_{i,j,p} - n_{i,j}),~n_{i,j,p}\leftarrow n_{i,j}\]
文档的Topic model抽取可以认为是一个大量(而非海量)数据运算,采用类MPI架构的分布式计算架构(例如spark)会比 MapReduce 效率更高
虽然LDA能够聚类,但是supervisord learning 对标签体系更有意义。
数据加工和交易
精准的广告业务是什么?下面的图将数据的加工过程类比于石油的加工和提炼的过程,在这个过程中,实际上与媒体的关系已经不大了。
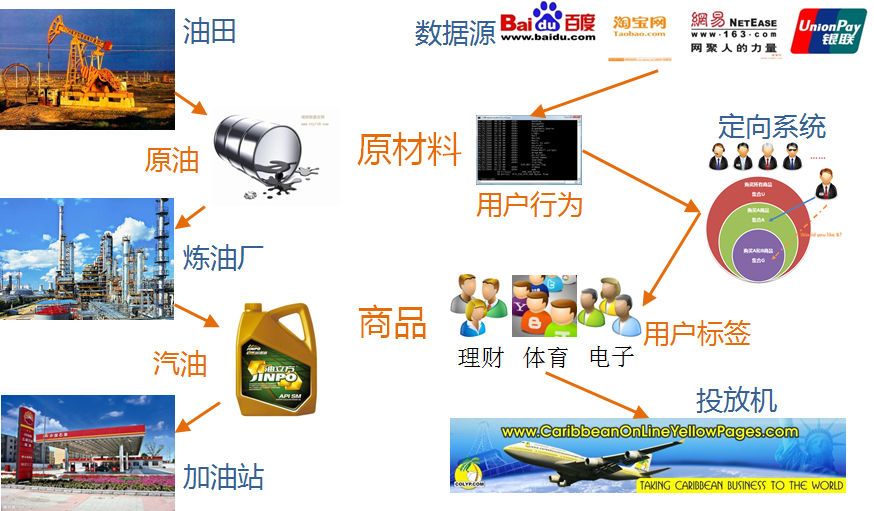
精准广告业务的若干值得探讨的观点
- 越精准的广告,给市场带来的价值越大
- 媒体利益与广告主利益是相博弈的关系
- 精准投放加上大数据可以显著提高营收
- 人群覆盖率较低的数据来源是不需要的(长尾?)
- 不同的广告产品应该采用不同的投放机
有价值的数据
下面列出了一些在广告系统中有价值的数据
- 用户标识
- 除上下文和地域外各种定向的基础,需要长期积累和不断建设
- 可以通过多家第三方ID绑定不断优化
- 用户行为
- 业界公认有效行为数据(按有效性排序)
- 交易,预交易,搜索广告点击,广告点击,搜索,搜索点击,网页浏览,分享,广告浏览
- 需去除网络热点话题带来的偏差
- 越靠近demand的行为对转化越有贡献
- 越主动的行为越有效
- 广告商(Demand)数据
- 简单的cookie植入可以用于retargeting。
- 对接广告商种子人群可以做look-alike,提高覆盖率。
- 用户属性和精确地理位置
- 非媒体广告网络很难获取,需通过第三方数据对接。
- 移动互联和HTML5为获得地理位置提供了便利性。
- 社交网络
- 朋友关系为用户兴趣和属性的平滑提供了机会
- 实名社交网络的人口属性信息相对准确
数据管理平台(Data Management Platform)
- 目的:
- 为网站提供数据加工和对外交易能力(如Audience Science)
- 加工跨媒体用户标签,在交易市场中售卖
- 是否应直接从事广告交易存在争议
- 关键特征:
- 定制化用户划分
- 统一的对外数据接口:demand端提供给supply端
- 代表:
- Bluekai, AudienceScience
DMP的系统架构示意图如下所示
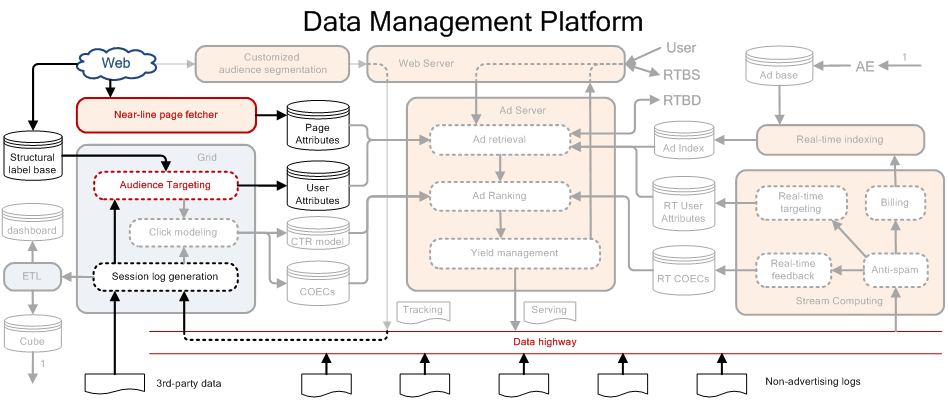
DMP主要是Data highway部分,主要完成两个工作: 1. 挖掘出各个用户的标签 2. 利用挖掘出来的用户的标签,售卖或使用
这里介绍一个Data Highway 的工具:Scribe
- 大规模分布式日志收集系统,可以准实时收集大量日志到 HDFS,利用Thrift实现底层服务
- 类似工具: Flume, Chukwa
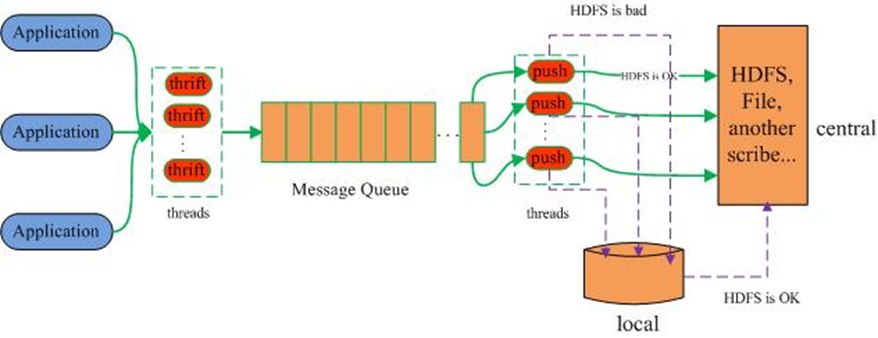
这个工具在 Facebook 经过实践,验证了其面对大规模数据时的可靠性。
下面介绍一下audience targeting 在业界的一种商业模式 上面提到了Bluekai这个公司,其核心业务主要有以下两个:
- 为中小网站主提供数据加工和变现的方式
- 通过汇聚众多中小网站用户资料和行为数据,加工成受众定向标签,通过Data exchange对外售卖
Bluekai 提供大量细分类别、开放体系上的标签,如“对宝洁洗发水感兴趣的人”,“想去日本旅游的人”;靠数据出售变现,并与提供数据的网站主分成,但是并不直接运营广告业务;对于设计用户隐私的问题,用户可以看到自己的资料被谁使用,也可以选择“捐给慈善机构”